

فرض کنید شما یک متخصص منابع انسانی هستید و می خواهید تعیین کنید:
- آیا سن یک کارمند تأثیر قابل توجهی بر بلوغ آنها دارد یا خیر
- اهمیت تجربه و توانایی بر پاداش
- اهمیت IQ (ضریب هوش) در مقابل EQ (ضریب عاطفی) بر توانایی رسیدگی به مشکلات
- چگونه سبک زندگی بی تحرک در محل کار بر خروجی کارمندان تأثیر می گذارد
- اگر یک فعالیت بدنی خاص باعث می شود کارکنان در محل کار پرانرژی و سرزنده تر شوند
همه اینها سناریوهای معمولی در یک سازمان هستند. اما تاثیر آنها بسیار زیاد است. چگونه، به عنوان یک متخصص منابع انسانی، می توانید تعیین کنید که کدام متغیرها چه تأثیری بر بهره وری کارکنان دارند؟
تحلیل رگرسیون به شما پاسخ می دهد. این به شما کمک می کند تا رابطه بین دو یا چند متغیر را توضیح دهید.
همراه با توضیح، مورد توجه قرار می گیرد!
با این حال، قبل از اینکه به جزئیات بپردازیم و بفهمیم که چگونه میتوان از مدلهای رگرسیون برای استخراج رابطه علت و معلولی استفاده کرد، چندین ملاحظات مهم وجود دارد که باید مورد توجه قرار گیرد:
- همه مفروضات را نمی توان آزمایش و تأیید کرد.
- شما باید با دقت یک فرضیه را ایجاد کنید تا به درستی کار کند.
- دقت نتایج به صحت داده ها بستگی دارد.
- نادیده گرفتن متغیرهای مهم می تواند ضرایب شما را سوگیری کند.
- مدل اقتصادسنجی که انتخاب میکنید باید با نوع دادهای که استفاده میکنید مطابقت داشته باشد.
مدل رگرسیون خطی
تجزیه و تحلیل رگرسیون برخی از موقعیت های بسیار پیچیده را تقریباً به طور جادویی ساده می کند. این به محققان و متخصصان کمک می کند تا متغیرهای در هم تنیده را به هم مرتبط کنند. رگرسیون خطی یکی از ساده ترین و رایج ترین مدل های رگرسیون است. رابطه علت و معلولی بین دو متغیر را پیش بینی می کند.
این مدل از روش حداقل مربعات معمولی (OLS) استفاده می کند که مقدار پارامترهای مجهول را در یک معادله رگرسیون خطی تعیین می کند. هدف آن به حداقل رساندن تفاوت بین پاسخ های مشاهده شده و پاسخ های پیش بینی شده با استفاده از مدل رگرسیون خطی است. برای استفاده از این مدل، الزامات خاصی وجود دارد که باید رعایت کنید. در غیر این صورت نتایج می تواند گیج کننده و مبهم باشد.
پیش نیازهای استفاده از مدل رگرسیون خطی
- تعداد مشاهدات محدود است.
- فرض اولیه این است که خطاهای ناچیز در مقدار متغیر مستقل (X) یا متغیرهای رگرسیون وجود دارد. از اصل برون زایی دقیق پیروی می کند که به معنای خطای صفر است.
- رگرسیورها یا متغیرهای مستقل باید ثابت یا متغیرهای تصادفی از پیش تعریف شده باشند.
- هرچه تفاوت بین نقطه داده مربوط به خط رگرسیون کوچکتر باشد، یک مدل اقتصادسنجی بهتر با داده ها مطابقت دارد.
- این تخمینگر حداکثر احتمال را فراهم می کند و مطابقت مدل اقتصادسنجی انتخاب شده را با داده های مشاهده شده به حداکثر می رساند.
بیایید آن را با کمک یک مثال درک کنیم:
پدیده این است: سابقه کار و دستمزد متغیرهای مرتبط هستند. مدل رگرسیون خطی می تواند به پیش بینی صفحه دستمزد یک کارمند با توجه به تجربه کاری او کمک کند.
نمایندگی آماری
حال مشکل این است که چگونه آن را به صورت آماری نشان دهیم.
دو خط رگرسیون وجود دارد – Y روی X و X روی Y.
Y در X زمانی است که مقدار Y ناشناخته است. X روی Y زمانی است که مقدار X ناشناخته است.
در اینجا نمایش های آماری آنها آمده است:
فرض کنید، ارزش پاداش = Y و ارزش تجربه = X است
|
انتخاب خط رگرسیون
نمایش آماری بالا نمونه ای برای نشان دادن چگونگی توسعه مدل های اقتصادسنجی در زمانی است که مقدار یکی از متغیرها مشخص و دیگری ناشناخته است. با این حال، این بدان معنا نیست که هر دو نمایش صحیح هستند .
این به این دلیل است که ممکن است دستمزد به تجربه کاری یک فرد بستگی داشته باشد، اما بالعکس درست نیست. تجربه به دستمزد بستگی ندارد. بنابراین، باید متغیر وابسته و سپس خط رگرسیون را با دقت انتخاب کنید.
معادله رگرسیون به چه معناست؟
معادله رگرسیون خطی درصد افزایش یا کاهش در مقدار متغیر وابسته (Y) را با درصد افزایش یا کاهش در مقدار متغیر مستقل (X) نشان می دهد.
فرض کنید مقادیر X و Y مشخص هستند.
میز 1
| ایکس | Y |
| 1 | 1 |
| 2 | 1.5 |
| 3 | 2.5 |
| 4 | 2.8 |
| 5 | 4 |
از نظر گرافیکی به صورت زیر نمایش داده می شود:
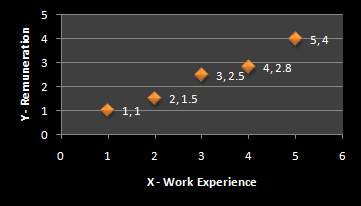
نمودار 1
چگونه بهترین خط رگرسیون را پیدا کنیم؟
با استفاده از روش حداقل مربعات معمولی!
اجازه دهید با مثال بالا ادامه دهیم:
جدول 2
| ایکس | Y | XY | X-X’ | بله | (X-X’) (Y-Y’) | (X-X’) 2 | (Y-Y’) 2 | |
| 1 | 1 | 1 | -2 | -1.16 | 2.32 | 4 | 1.346 | |
| 2 | 1.5 | 3 | -1 | -0.66 | 0.66 | 1 | 0.436 | |
| 3 | 2.5 | 7.5 | 0 | 0.34 | 0.34 | 0 | 0.116 | |
| 4 | 2.8 | 11.2 | 1 | 0.64 | 0.64 | 1 | 0.410 | |
| 5 | 4 | 20 | 2 | 1.84 | 3.68 | 4 | 3.386 | |
| مجموع | 15 | 10.8 | 42.7 | 7.64 | 10 | 5.69 | ||
| منظور داشتن | X’ = 3 (15/5) | Y’ = 2.16 (10.8/5) |
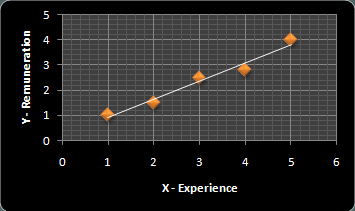
نمودار 2
Y = a + b(X) +e (اصطلاح خطا)
در این حالت e صفر است زیرا فرض می شود که متغیر مستقل (X) دارای خطاهای ناچیز است.
بنابراین، Y = a + b(X) باقی می ماند.
اکنون مقدار b را پیدا می کنیم.
b = [ ∑ XY – (∑Y)(∑X)/n ] / ∑(X-X’) 2
مقادیر فرمول بالا را جایگزین کنید:
b = [ 42.7 – (15*10.8)/5]/10 = [ 42.7 – 162/5]/10 = [ 42.7 – 32.5]/10 = 10.2/10 = 1.02
b = 1.02
بنابراین ،
a = Y – b (X)
a = Y – 1.02 (X) یا a = ∑Y/n – 1.02 (∑X/n)
a = 2.16 – 1.02 * 3 = 2.16 – 3.06
a = -1.06
با جایگزین کردن مقادیر a، b و X، میتوانیم مقدار مربوط به Y را پیدا کنیم .
Y = a + b(X) = -1.06 + 1.02X
وقتی X = 1
Y = -1.06 + 1.02*1 = -0.04
وقتی X = 2
Y = – 1.06 + 1.02 * 2 = 0.98
وقتی X = 3، Y می شود 2
هنگامی که X = 4، Y خواهد بود 3.02
هنگامی که X = 5، Y خواهد شد 4.04
جدول 3
| ایکس | Y |
| 1 | -0.04 |
| 2 | 0.98 |
| 3 | 2 |
| 4 | 3.02 |
| 5 | 4.04 |
بهترین برازش خط رگرسیون خواهد بود:
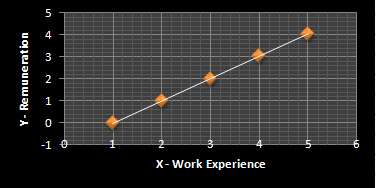
نمودار 3
- خط رگرسیون از X’ می گذرد که در این مورد 3 است. (به نمودار 3 مراجعه کنید)
- b، ضریب رگرسیون X، یک تغییر متوسط در Y است. در این حالت، b = 1.02 که میانگین تغییر در مقادیر y است: -0.04، 0.98، 2، 3.02 و 4.04. (به جدول 3 مراجعه کنید)
- خط رگرسیون از Y’ می گذرد که در این مورد 2.16 است. (به نمودار 3 مراجعه کنید)
ضریب تعیین – ارزیابی نیکویی برازش
هر زمان که از یک مدل رگرسیون استفاده می کنید، اولین چیزی که باید در نظر بگیرید این است که چگونه یک مدل اقتصادسنجی با داده ها مطابقت دارد یا یک معادله رگرسیون چقدر با داده ها مطابقت دارد.
اینجاست که مفهوم ضریب تعیین مطرح میشود . مدلهای رگرسیون معمولاً با استفاده از این رویکرد برازش میشوند.
تعیین می کند که تا چه حد می توان متغیر وابسته را از متغیر مستقل پیش بینی کرد. برازش مناسب مدل رگرسیون حداقل مربعی معمولی را ارزیابی می کند.
با R 2 نشان داده می شود، مقدار آن بین 0 و 1 قرار دارد.
- R 2 = 0: مقدار متغیر وابسته را نمی توان از متغیر مستقل پیش بینی کرد.
- R 2 = 1، مقدار متغیر وابسته را می توان به راحتی از روی متغیر مستقل پیش بینی کرد. هیچ خطایی در داده ها وجود ندارد.
هرچه مقدار R 2 بیشتر باشد، مدل بهتر با داده ها تناسب دارد.
بیایید اکنون نحوه محاسبه R 2 را درک کنیم . فرمول پیدا کردن R2 به صورت زیر است:
R 2 = { (1 / n) * ∑ (X-X’) * (Y-Y’) } / (σx * σy) 2
جایی که n = تعداد مشاهدات = 5
∑ (X-X’) * (Y-Y’) = 7.64 (مرجع جدول 2)
σx انحراف معیار X و σy انحراف معیار Y است
σx = جذر ∑ (X-X’) 2 /n = √10/5 = √ 2 = 1.414
σy = جذر ∑ (Y-Y’) 2 /n = √5.69/5 = √1.138 = 1.067
حالا بیایید مقدار R 2 را تعیین کنیم
R 2 = { 1/5 (7.64) } / (1.414 * 1.067) 2 = 1.528 / (1.509) 2 = 1.528/2.277 = 0.67
بنابراین R2 = 0.67
هر چه مقدار ضریب تعیین بالاتر باشد، خطای استاندارد کمتر می شود. نتیجه نشان می دهد که حدود 67 درصد از تغییرات در دستمزد را می توان با تجربه کاری توضیح داد. نشان می دهد که سابقه کار نقش عمده ای در تعیین دستمزد دارد.
ویژگی های برآوردگرها
- b بی طرف و مستقل است.
- σx به دلیل برون زایی دقیق بی طرف است. در صورت برون زایی غیر دقیق، مقدار در نمونه های محدود بایاس می شود.
- (σy) 2 بایاس است اما جذر خطا را به حداقل می رساند.
مدل رگرسیون خطی زمانی استفاده می شود که رابطه خطی بین متغیرهای وابسته و مستقل وجود داشته باشد. زمانی که مقدار یک متغیر وابسته بر اساس چندین متغیر (بیش از یک) باشد، از تحلیل رگرسیون چندگانه استفاده می کنیم. در مقاله بعدی در مورد این موضوع مطالعه خواهیم کرد . گوش به زنگ باشید!
بدون نظر