

ابزارهای آماری و کاربرد آنها – تحلیل رگرسیون
برای یافتن رابطه بین مجموعه ای از متغیرها از نظر آماری می توان از تحلیل رگرسیون استفاده کرد. این کار با شناسایی منحنی یا خطی که به بهترین وجه با متغیرهای ارائه شده مطابقت دارد، انجام می شود. تجزیه و تحلیل رگرسیون به طور گسترده در تحقیقات بازاریابی برای تجزیه و تحلیل روند و برای پیش بینی استفاده می شود. در این مقاله فقط رگرسیون خطی ساده را توضیح خواهیم داد.
توضیح بر اساس مورد
از آنجایی که استفاده از اعداد و انجام برخی محاسبات برای بیان مفهوم رگرسیون اجتناب ناپذیر است، در طول مقاله موردی را برای توضیح بخش آماری به روشی آسان نشان خواهیم داد.
فرض کنید پس از چند سال کار در صنعت، فردی تصمیم می گیرد برای کسب مهارت های اضافی به دانشگاه برود. از آنجایی که این روزها تحصیل گران است، فرد می خواهد بداند که آیا تحصیل واقعاً حقوق را افزایش می دهد یا خیر.
برای شروع، باید ببینیم انتظار می رود با هر سال اضافی که در دانشگاه سپری می شود، دستمزد چقدر افزایش یابد. راه شهودی برای انجام آن این است که نمونهای از افراد را بررسی کنیم و از هر یک از آنها بپرسیم که چقدر درآمد دارند و چند سال در مدرسه گذراندهاند و سپس تعیین میکنیم که آیا میتوانیم الگویی را در پاسخهای آنها مشاهده کنیم. برای سادگی و توضیح، بیایید بگوییم که ما از 10 نفر نظرسنجی می کنیم (در واقع برای به دست آوردن نتایج قابل اعتماد، حجم نمونه بسیار بزرگتر مورد نیاز است). یک نمونه تصادفی از 10 نفر، 10 نقطه داده ایجاد می کند. نمودار پراکندگی در اکسل بهترین راه برای نشان دادن این است. تحصیلات متغیر مستقلی است که روی محور X نشان داده شده است و دستمزد متغیر وابسته است که باید روی محور Y رسم شود. الگوی کلی در مجموعه داده را می توان تعیین کرد، به عنوان مثال رابطه بین دستمزد و تحصیلات را می توان با نقاط نمودار پراکندگی بدست آورد. به عنوان مثال، فرض کنید یک نفر به نام P1 دارای 13 سال تحصیلات است و 20 دلار در ساعت درآمد دارد. نفر بعدی، P2، 20 سال تحصیلات دارد و 30 دلار در ساعت پرداخت می کند.
معادله یک خط Υ = mX + b است که در آن m شیب و b نقطه قطع است، یعنی جایی که خط محور y را قطع می کند. ما باید این خط بهترین تناسب را پیدا کنیم که نشان دهنده الگوی کلی در نمونه باشد. در تحلیل رگرسیون، خط به صورت Υ = β0+ β1X نمایش داده می شود. ما به سادگی نماد را تغییر دادیم: β0 نقطه قطع و β1 شیب گرادیان خط است. بسته های نرم افزاری مانند اکسل و متلب می توانند خط رگرسیون را تخمین بزنند.
بنابراین معادله اکنون تبدیل می شود:
دستمزد = β0 + β1 تحصیلات
وضعیت 1
برای تعیین اینکه آیا رابطه ای بین دستمزد و تحصیلات وجود دارد، β1، شیب خط رگرسیون را مشاهده کنید. اگر β1 مثبت باشد، بین دستمزد و تحصیلات رابطه مثبت وجود دارد. هر چه فرد تحصیلات بیشتری کسب کند، دستمزد بالاتری خواهد داشت. این با نمودار زیر روشن می شود:
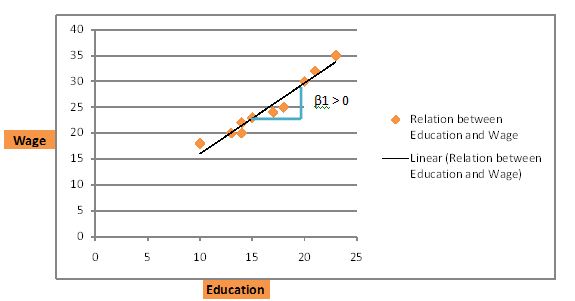
اگر داده های نظرسنجی مانند نمودار زیر باشد، یک رابطه منفی وجود دارد. خط رگرسیون از چپ به راست به سمت پایین شیب دارد. روند در اینجا این است که هر چه یک فرد تحصیلات بیشتری داشته باشد، دستمزد کمتری دریافت می کند.
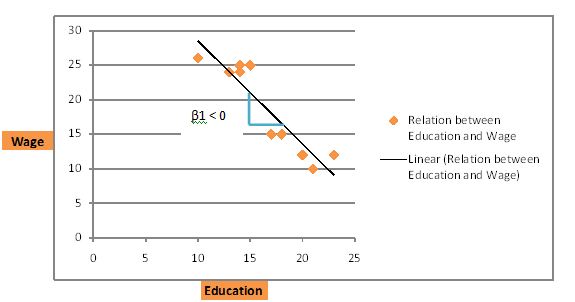
سناریوی سوم زمانی است که بین دستمزد و تحصیلات ارتباطی وجود ندارد. در آن صورت، خط داده ها را به صورت زیر قطع می کند. خط بهترین تناسب یک خط افقی است.
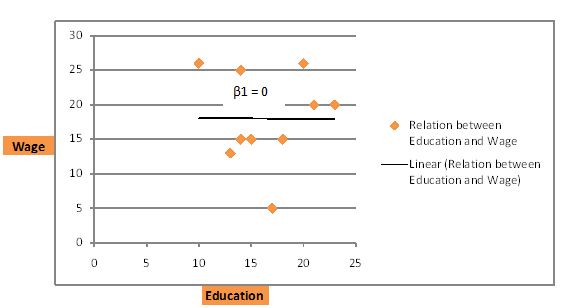
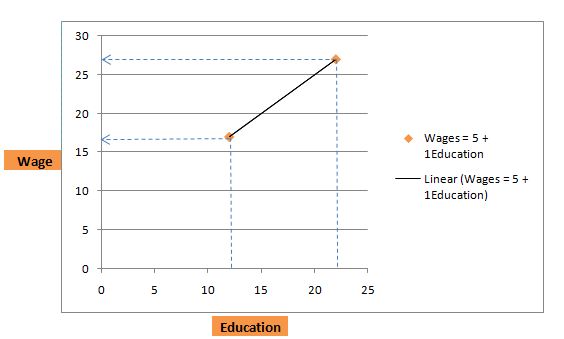
فرض کنید فردی به تازگی دبیرستان را تمام کرده و 12 سال تحصیل کرده است. با جایگزینی مقدار معادله فوق، دستمزد ساعتی را به صورت زیر بدست می آوریم:
دستمزد = 5 + 1 × 12 = 17
فرد بعدی با 22 سال تحصیل، دستمزد مورد انتظار او خواهد بود:
دستمزد = 5 + 1×22 = 27، یعنی 27 دلار در ساعت.
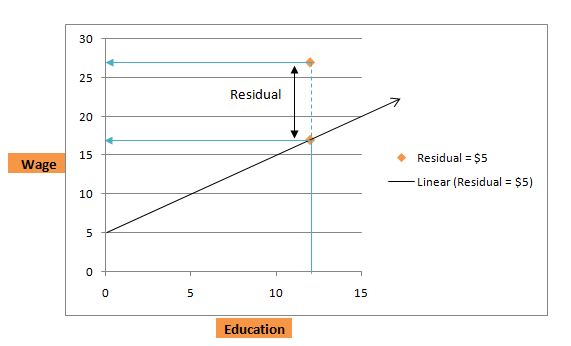
باقیمانده ها
با اشاره به معادله فرد P1 در بالا با 12 سال تحصیل، فرد 17 دلار در ساعت درآمد دارد. با این حال فرض کنید در واقعیت متوجه میشویم که آن شخص در هر ساعت ۲۲ دلار درآمد دارد! این بدان معنا نیست که معادله رگرسیون نادرست است، اما در واقع می توان آن را به عاملی نسبت داد که به عنوان باقیمانده نامیده می شود. بنابراین باقیمانده تفاوت بین دستمزد واقعی و دستمزد پیش بینی شده است. بنابراین برای P1، باقیمانده 22-17 = 5 ($) است. مدل رگرسیون بهترین حدس در دستمزد ساعتی با توجه به سطح تحصیلات است. با این حال، در زندگی واقعی، علاوه بر تحصیل، بسیاری از عوامل دیگر مانند تعداد سال تجربه، IQ، توانایی شبکه، قد و غیره.
آنها در نظر گرفته نشدند و در عبارت باقیمانده نشان داده شده با μ هستند. بنابراین معادله اصلاح شده اکنون به صورت زیر خواهد بود:
Υ = β0+ β1X + μ
خلاصه
مهمترین نکات مهم مقاله فوق به شرح زیر است:
- خط رگرسیون خط بهترین تناسب است. این خطی است که روند یا رابطه را در داده های داده شده به بهترین شکل نشان می دهد
- ß1 شیب خط است. رابطه بین متغیر وابسته و مستقل به صورت زیر است:
- مثبت اگر: β1 > 0
- منفی اگر: β1 < 0
- هیچ رابطه ای وجود ندارد اگر: β1 = 0
- رگرسیون تخمینی را می توان برای پیش بینی X با توجه به Υ استفاده کرد.
- باقیمانده = واقعی – پیش بینی شده
- عبارت باقیمانده خطای پیشبینی را محاسبه میکند. این شامل همه عوامل دیگر (به جز X) است که بر Y تأثیر می گذارد.
بدون دیدگاه